PDFontFixer-v1.3 修复PDF文档不能复制粘贴问题
软件使用方法:
1、文件菜单打开PDF。或者直接拖拽文档到软件窗口。
2、点击字体名称,查看字体属性,是否嵌入。本软件只处理嵌入字体,不处理Type3类型的pdf自绘字体。
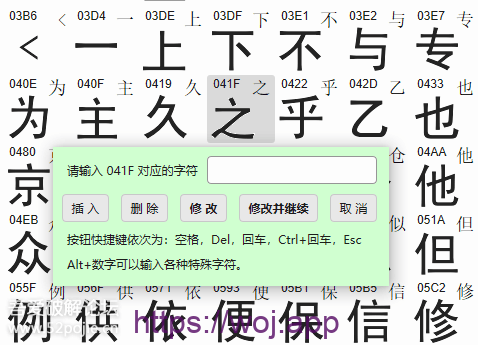
3、按F4,识别右侧窗口中渲染出来的全部字符。点击字符图像可以人工校正。具有插入、删除、修改、修改并继续,等多个功能。
4、按F2,保存当前字体的Unicode映射。
5、如此循环,处理全部需要补充映射的字体。
6、文件菜单--保存PDF
运行环境:
1、由于使用最新的Direct2D构建UI,操作系统要求Windows 22H2或更高,64位操作系统。并安装最新补丁。
2、需要CPU支持SSE4.2、AES、AVX2指令集,否则本软件无法启动。
3、需要显卡支持DirectX 11, Direct 2D。
4、由于OCR比较吃CPU和内存,运行速度与CPU和内存大小有关。电脑配置不要低于8G内存。处理大量字体建议32G内存。
5、不支持Windows7、8、vista和早期的Windows10版本(低于1809)。
6、不支持32位操作系统。
经常遇到PDF文件可以浏览,但是无法复制粘贴文本的问题。复制文本之后粘贴到记事本,就会发现乱码。

为什么复制粘贴就乱码了呢?这就要提到一个字体中的概念----Unicode映射。字体文件的本质就是矢量绘图,而复制粘贴需要知道文字的Unicode码,把这个码放到剪贴板里面,其它的软件才会知道是什么字。正规的字体文件,都会带一个Unicode映射表,这个表会告诉软件字体中的第几个字对应的是Unicode中的哪一个字的编码。然后我们才能正确地复制粘贴。由于某些PDF文档在制作的时候,有意将Unicode映射表删掉了,造成我们无法得知复制的字对应的是Unicode的哪一个字,所以无法复制粘贴文档中的文本。这是一个很简单,也很有效的文档反拷贝手段。
为了解决这个问题,我写了一个软件PDFontFixer v1.0,采用OCR识别PDF文档中的字体里面的每一个字形,得到对应的Unicode编码,再将这些编码做成ToUnicode映射表,保存到PDF文档的字体里。这样,我们就可以正常复制粘贴文本了。
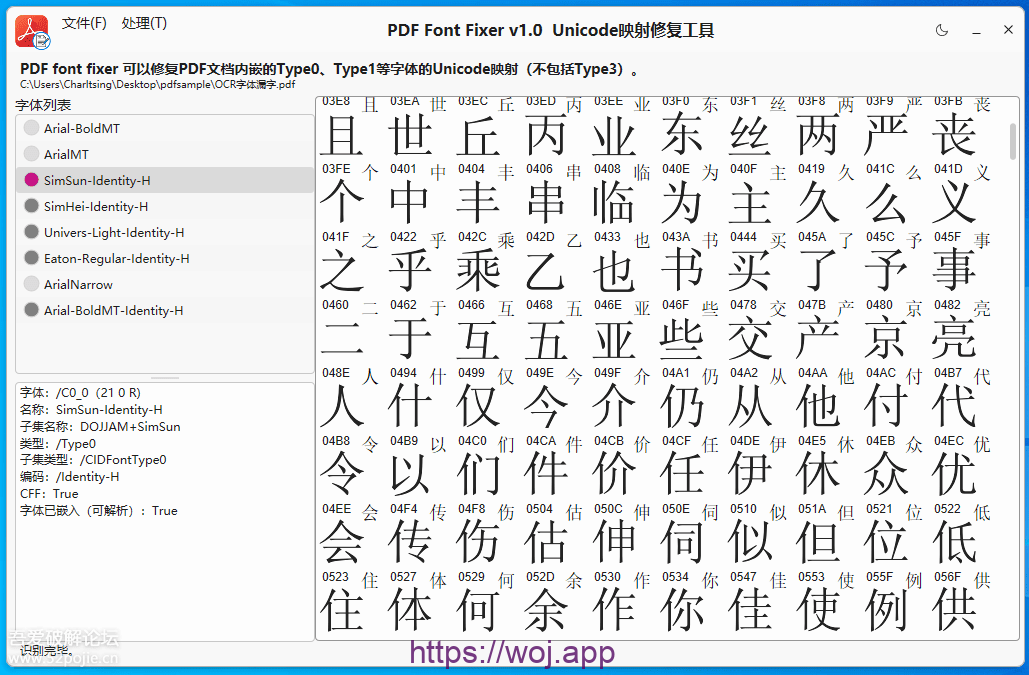
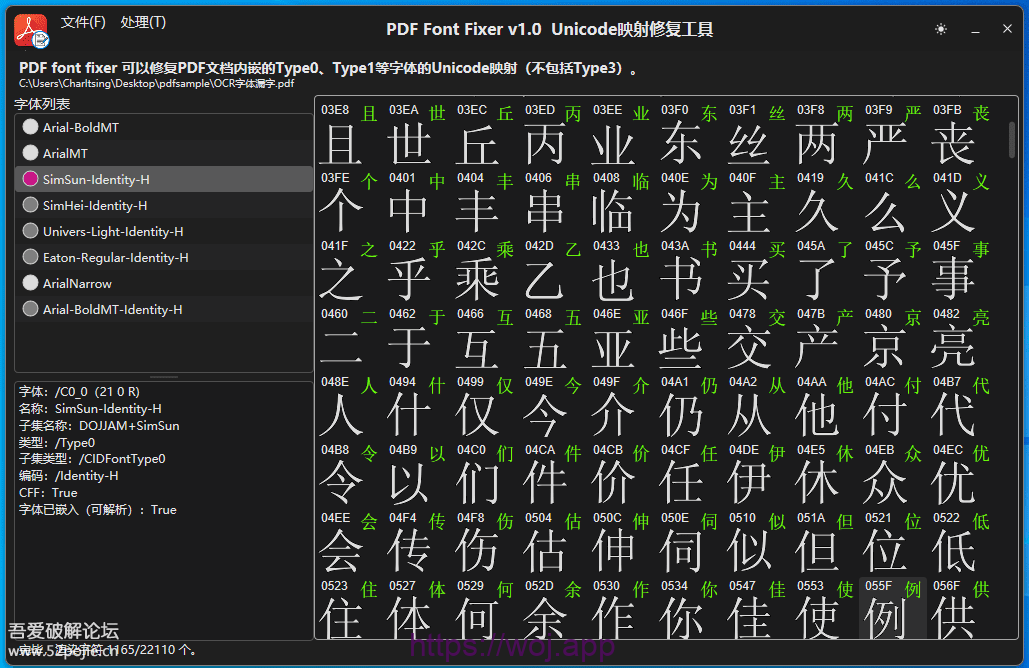
其实,修复PDF字体并不难,市面上也有若干软件支持修复,只是大多为商业版。实现字体修复的难点不在于为PDF字体创建Unicode映射,而在于如何快速准确识别几百~几千个汉字。前些年不怎么具备本机仅使用CPU进行快速OCR的条件,去年随着OCR小模型的进步,目前已经可以实现本机使用普通CPU对汉字进行快速识别。经测试,小模型仅依赖CPU就可以对印刷体汉字进行识别,几百个汉字图像的识别耗时只有1~2秒。不考虑特殊符号的话,实测识别准确率可以达到100%。这就给PDF修复字体缺失的Unicode映射解决了最大的麻烦。
于是,PDFontFixer v1.0诞生了。
蓝奏云下载 v1.3下载 https://charltsing.lanzoum.com/iFfmB3mn6ekj
需要说明的是,按照PDF规范推荐,每页的汉字要求采用字体子集的方式嵌入在页面资源当中。字体子集最大的数量一般不超过3000个汉字,大部分在几百~一两千之间。字体子集的好处是渲染页面速度快。坏处自然也很明显,如果每页一个字体子集的话,整个文档假如有1000页,那就是一千个字体。然而,实际上很多文档为了排版好看,经常在一个页面嵌入十几个乃至几十个字体。这样整个文档的字体数量就非常可观了。即使字体子集可以复用,整个文档的字体数量也会有几百个。如果没有复用,那么整个文档的字体数量会多达两三万个。
考虑到需要人工审核OCR结果并进行个别字符的校正,所以,字体修复是一个极其耗时的工作。
下载地址:https://charltsing.lanzoum.com/iFfmB3mn6ekj
文章来源:https://www.52pojie.cn/forum.php?mod=viewthread&tid=2101607&extra=&authorid=2417690&page=1
布施恩德可便相知重
微信扫一扫打赏
支付宝扫一扫打赏