A-A+
dify 编写数据分类分级判断模型

【注意:此文章为博主原创文章!转载需注意,请带原文链接,至少也要是txt格式!】
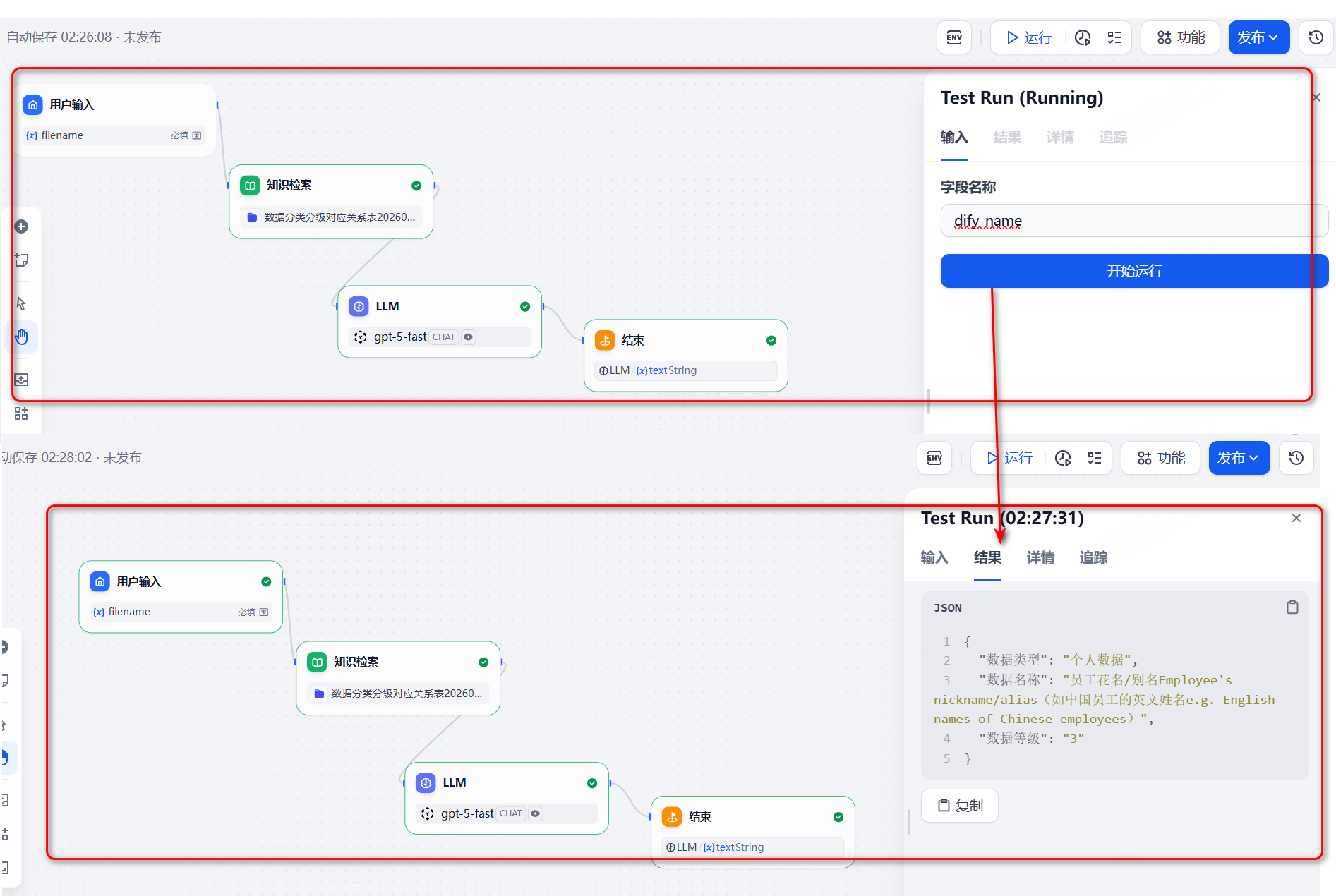
如下图,整个AI工作流分为4个步骤。
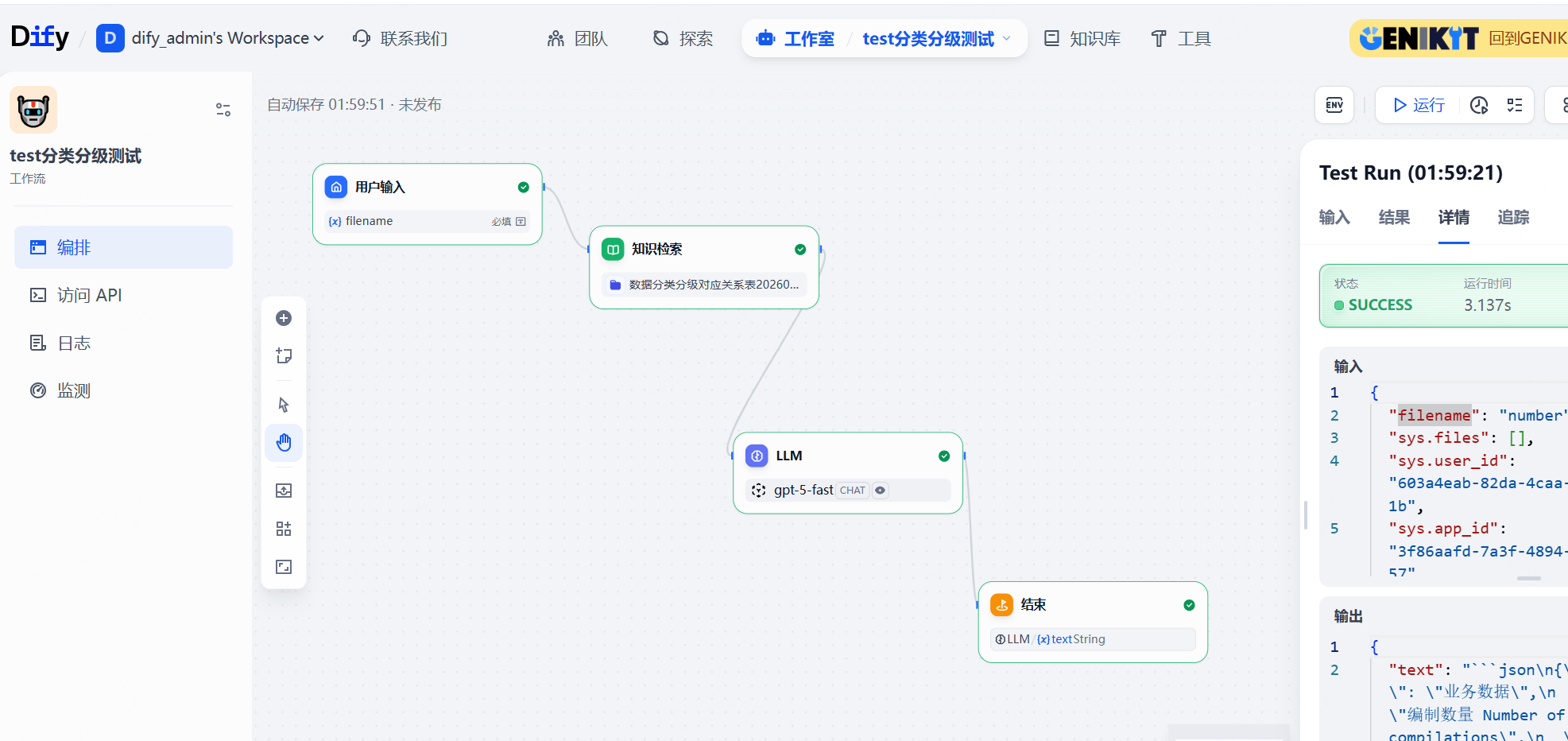
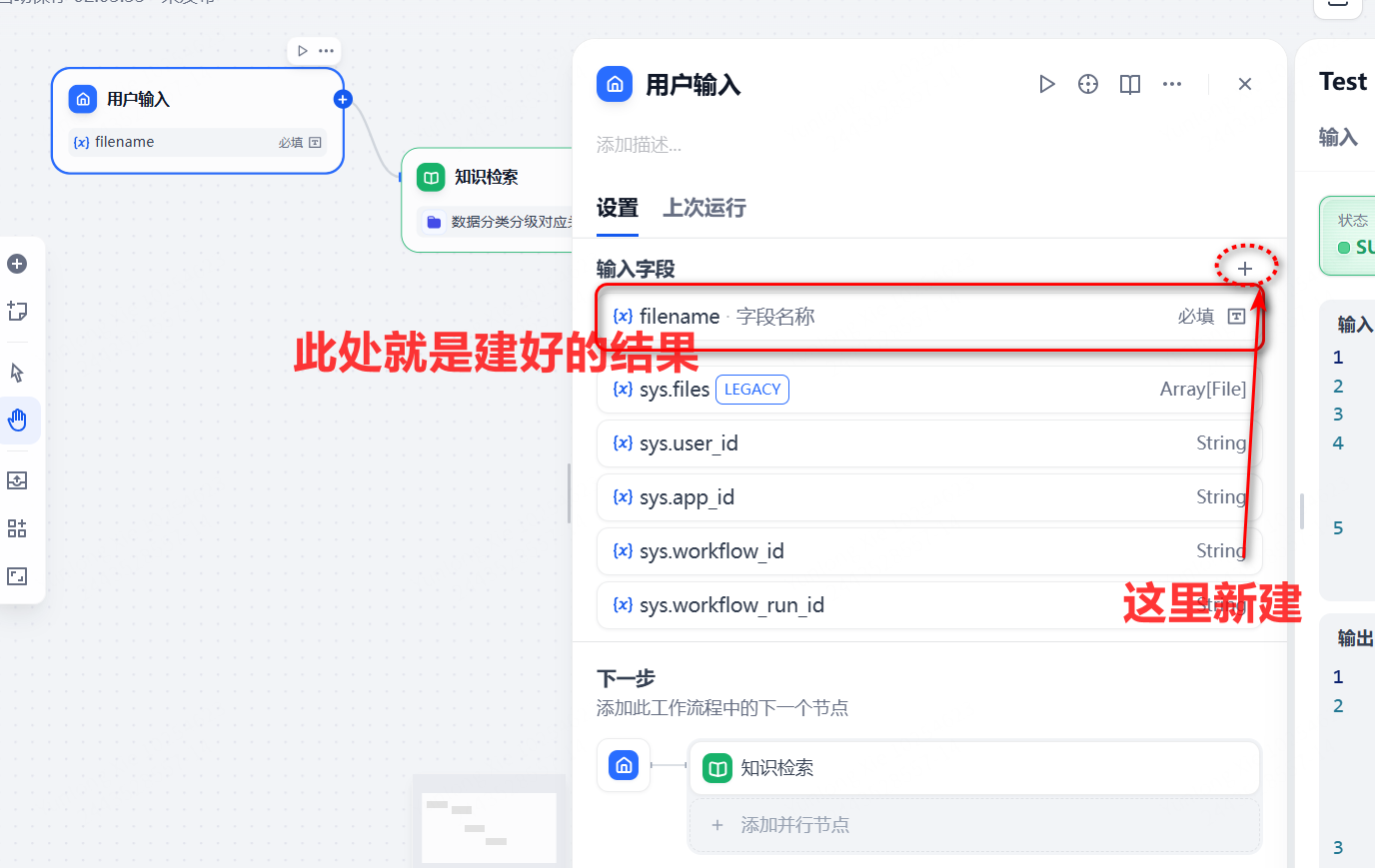
第一个步骤是开始,改名为《用户输入》,一般员工针对数据库字段进行打标,输入的也就是一个字段的名字而已,如"id"等,所以这里只需要放一个必填的字段即可。如下图:
有了用户输入,下一步就是根据用户输入进入向量知识库进行检索,不过这个时候就要建立一个对应的知识库了,一般都是把数据向量化,这样搜索的速度更快,准确度也能更高一些。所以是,先建立一个知识库,然后建立”知识检索“,检索刚刚建立的知识库。
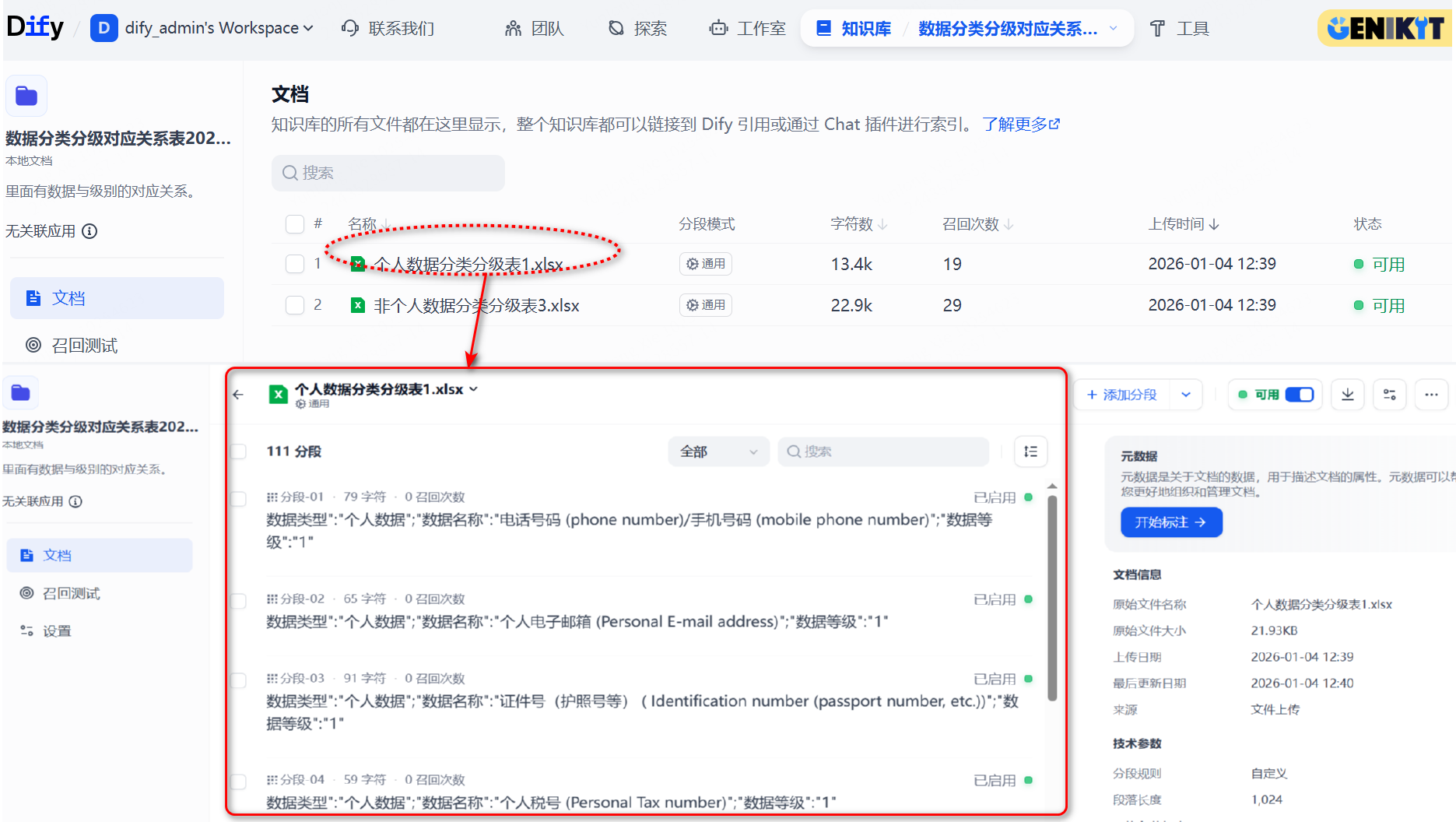
自己整理的数据,把数据的格式编辑一下,最好变成固定的格式类型,便于后续gpt进行识别匹配。
然后下一步就是把搜索的内容、检索的结果一并喂给AI,然后不断的优化prompt,输出AI的最终意见。
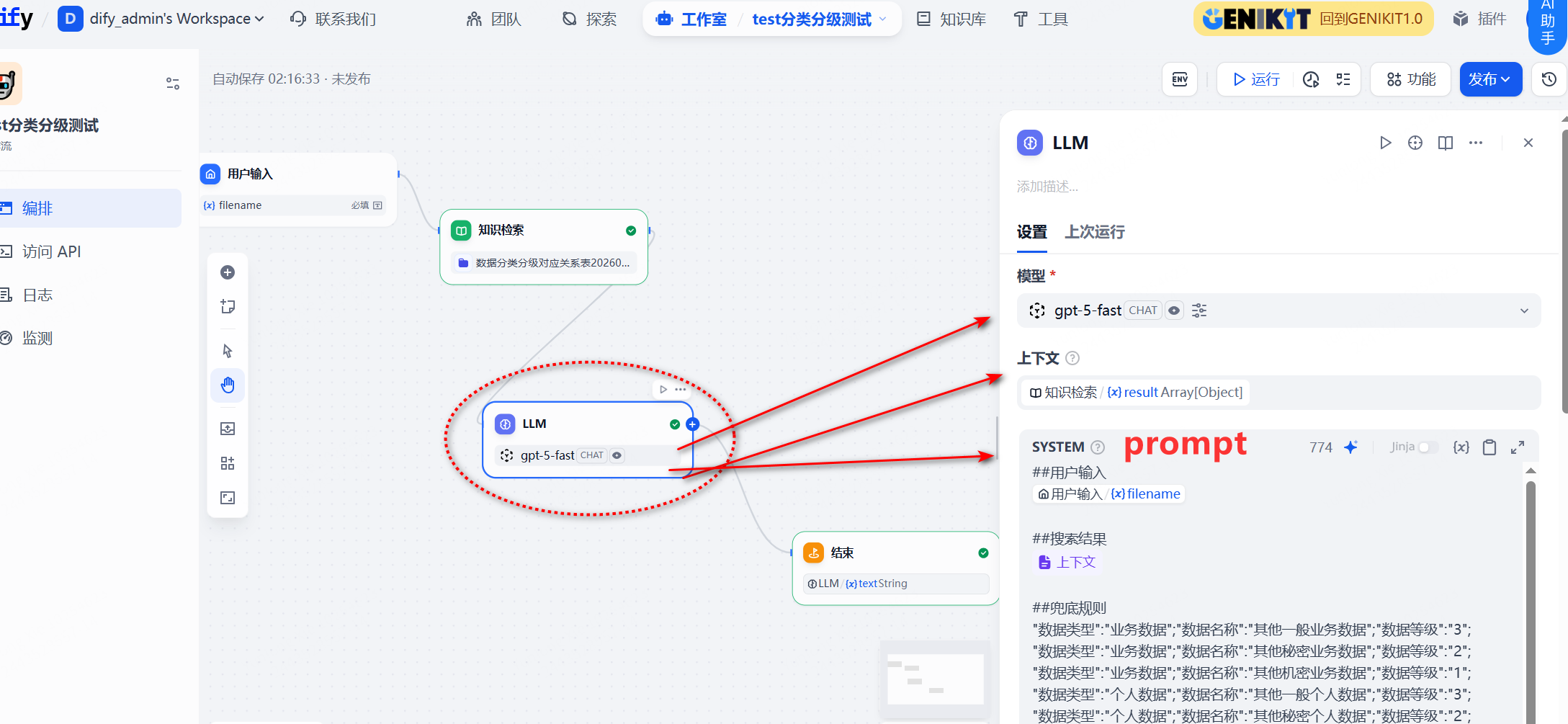
这里我给出我的prompt,可以供大家参考吧:
##用户输入
{{#1767528892770.filename#}}
##搜索结果
{{#context#}}
##兜底规则
"数据类型":"业务数据";"数据名称":"其他一般业务数据";"数据等级":"3";
"数据类型":"业务数据";"数据名称":"其他秘密业务数据";"数据等级":"2";
"数据类型":"业务数据";"数据名称":"其他机密业务数据";"数据等级":"1";
"数据类型":"个人数据";"数据名称":"其他一般个人数据";"数据等级":"3";
"数据类型":"个人数据";"数据名称":"其他秘密个人数据";"数据等级":"2";
"数据类型":"个人数据";"数据名称":"其他机密个人数据";"数据等级":"1";
##Role
你是一名信息安全数据合规专家,你的任务是基于搜索到的《数据分类分级对应关系表》上下文,对用户输入的数据进行匹配、定级,并按特定格式输出,请注意绝对不要凭空捏造新的不存在搜索结果里面的分类分级数据。
**绝对禁止**输出任何不在 搜索结果 中出现的数据类型、数据名称、数据等级或判断结论,严禁用常识补全标准条目。
##Knowledge Base Structure (Context Definition)
你看到的搜索结果上下文来每行基于;符号进行分割。数据类型仅分为个人数据、业务数据,每条数据都有对应的"数据名称"及"数据等级",请根据搜索结果中出现的字段特征,匹配与其对应关系最近的"数据类型"、"数据名称"。得到最终匹配结果后,请再与"兜底规则"里面的"数据类型"、"数据名称"进行对比,结合用户输入的内容选择最贴近结果,如果用户输入的内容与搜索结果不相近,则选择最相近的那条"兜底规则",然后请一定完整输出对应结果的当前行的数据,按标准的json格式输出。
最后一步就是必须要有一个输出,要展示AI结合prompt输出的结果,如下图:
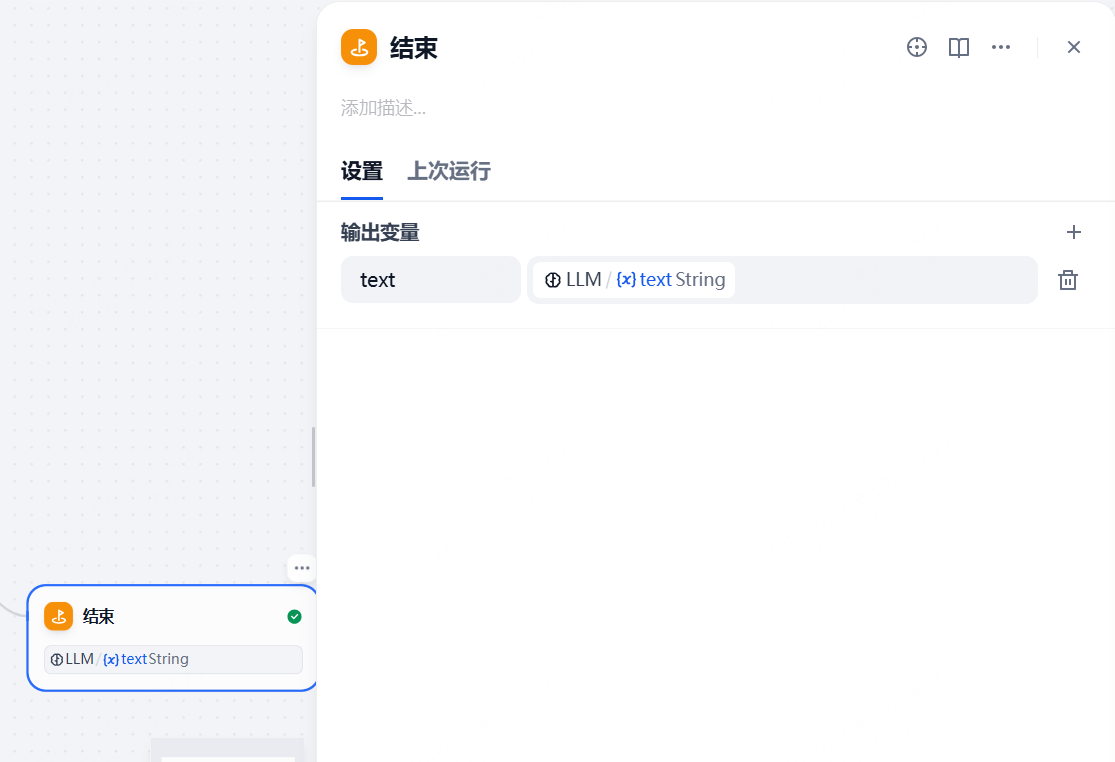
这样,一个完整的AI工作流就算建立完毕了。
布施恩德可便相知重
微信扫一扫打赏
支付宝扫一扫打赏