在跑GPU的时候,出现错误:
ImportError: libcudnn.so.7: cannot open shared object file: No such file or directory
原因:
默认软链的cudnn中没有相应的 libcudnn.so文件。
一探究竟:
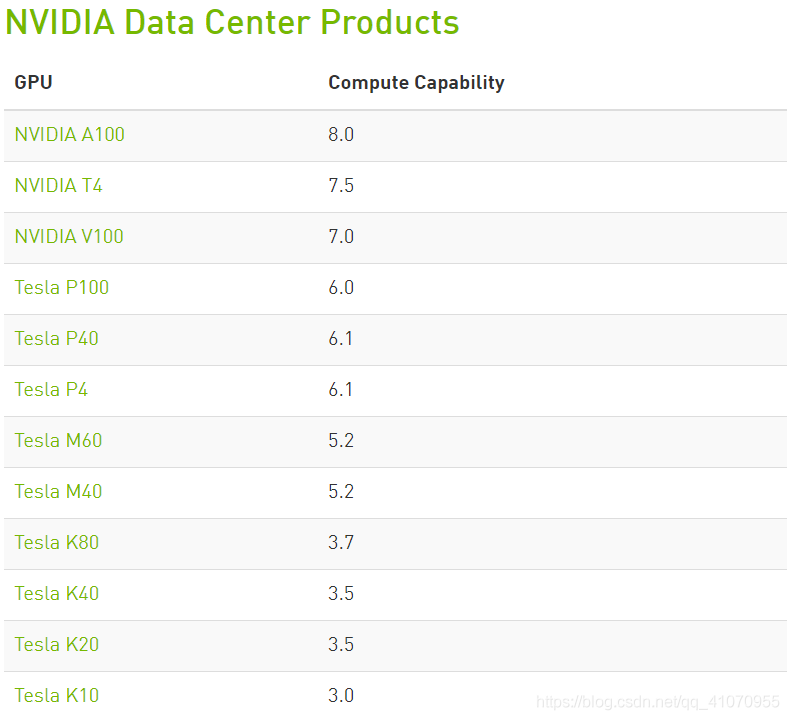
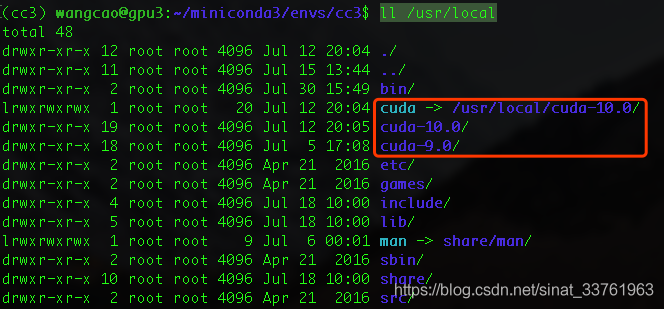
(1)执行命令ll /usr/local,查看该路径下的cuda:,显示有2个版本,cuda-10.0和cuda-9.0,并且cuda软链到了10.0的版本。
(2)那么来查看cuda-10.0的路径下是否有libcudnn.so文件呢,...
在 Windows 上安装 Detectron2 并不是一件容易的事,因为正式版的 Detectron2 在这个平台上是官方不支持的,而且 Windows Subsystem for Linux 也无法访问机器的 GPU。按照接下来的步骤,您可以快速安装和使用最新版本的Detectron2,完美运行。
第 1 步:创建 conda 环境
此步骤不是必需的。您可以使用下面描述的两个命令行创建一个空环境来测试 detectron2:https://docs.c...