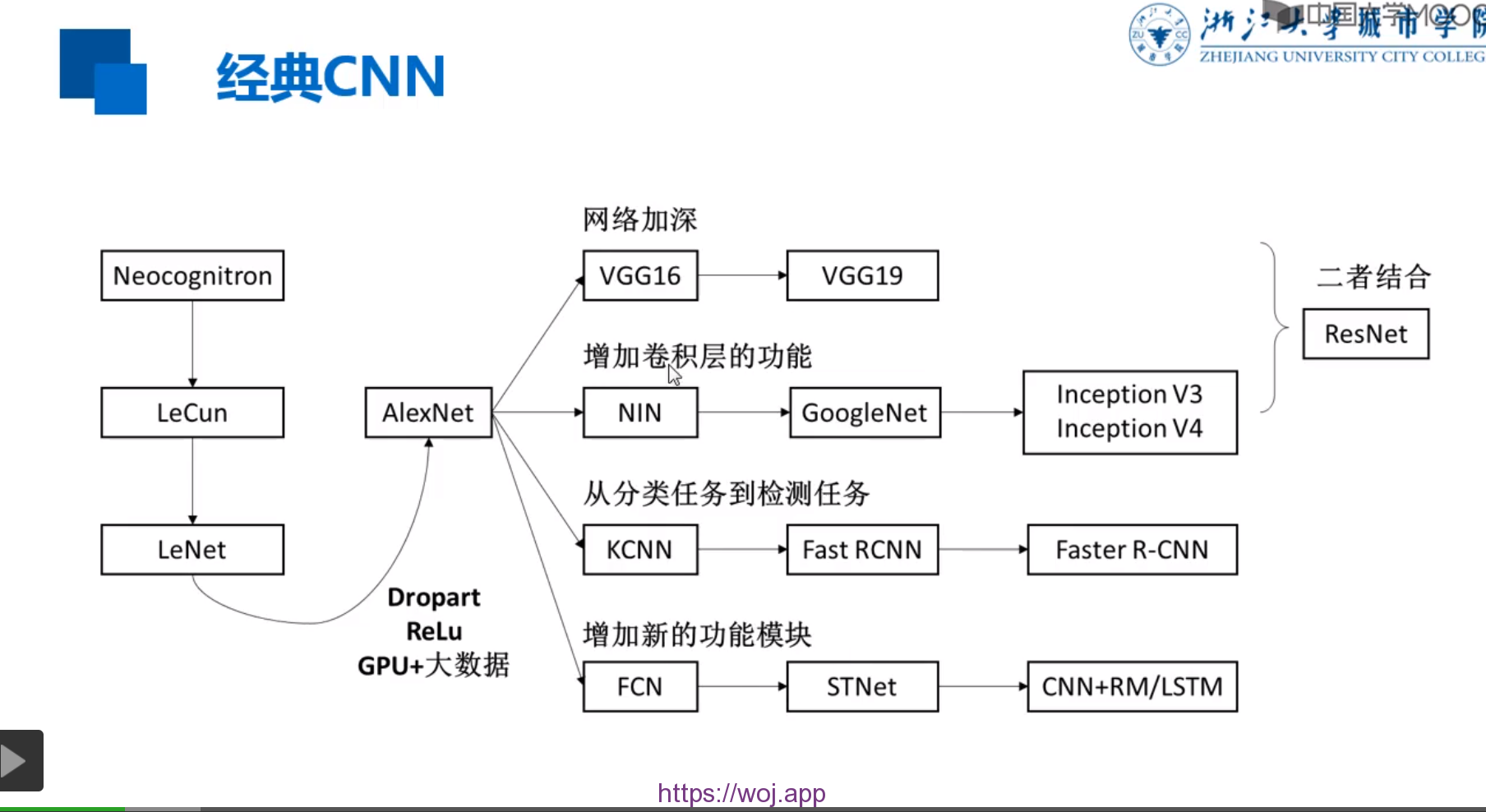
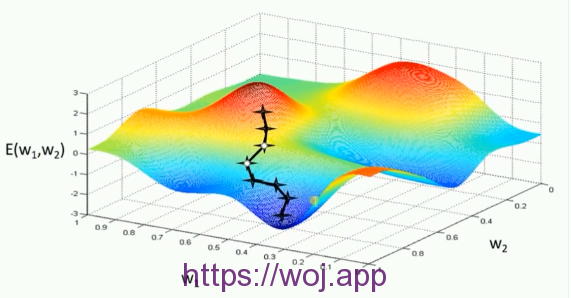
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
text1 = "学习keras的Tokenizer"
text2 = "就是这么简单"
texts = [text1, text2]
"""
# num_words 表示用多少词语生...