TensorFlow核心教程 时间序列预测 Time series forecasting 模型time_series.ipynb说明
Time series forecasting
本教程是使用递归神经网络(RNN)进行时间序列预测的简介。这包括两个部分:首先,您将预测单变量时间序列,然后将预测多变量时间序列。
1 2 3 4 5 6 7 8 9 10 | import tensorflow as tf import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import os import pandas as pd mpl.rcParams['figure.figsize'] = (8, 6) mpl.rcParams['axes.grid'] = False |
本教程使用[由马克斯·普朗克生物地球化学研究所记录的天气时间序列数据集。
该数据集包含14个不同的特征,例如气温,大气压力和湿度。从2003年开始,每10分钟收集一次。为了提高效率,您将仅使用2009年至2016年之间收集的数据。数据集的这一部分由FrançoisChollet为他的《Python深度学习》一书准备。
1 2 3 4 5 6 7 8 | zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
df = pd.read_csv(csv_path)
##让我们看一下数据。
df.head() |
###运行结果
从https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip下载数据 13574144/13568290 [==============================]-0s 0us / step
| Date Time时间 | p (mbar) | T (degC)温度 | Tpot (K) | Tdew (degC) | rh (%) | VPmax (mbar) | VPact (mbar) | VPdef (mbar) | sh (g/kg) | H2OC (mmol/mol) | rho (g/m**3) | wv (m/s) | max. wv (m/s) | wd (deg) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01.01.2009 00:10:00 | 996.52 | -8.02 | 265.40 | -8.90 | 93.3 | 3.33 | 3.11 | 0.22 | 1.94 | 3.12 | 1307.75 | 1.03 | 1.75 | 152.3 |
| 1 | 01.01.2009 00:20:00 | 996.57 | -8.41 | 265.01 | -9.28 | 93.4 | 3.23 | 3.02 | 0.21 | 1.89 | 3.03 | 1309.80 | 0.72 | 1.50 | 136.1 |
| 2 | 01.01.2009 00:30:00 | 996.53 | -8.51 | 264.91 | -9.31 | 93.9 | 3.21 | 3.01 | 0.20 | 1.88 | 3.02 | 1310.24 | 0.19 | 0.63 | 171.6 |
| 3 | 01.01.2009 00:40:00 | 996.51 | -8.31 | 265.12 | -9.07 | 94.2 | 3.26 | 3.07 | 0.19 | 1.92 | 3.08 | 1309.19 | 0.34 | 0.50 | 198.0 |
| 4 | 01.01.2009 00:50:00 | 996.51 | -8.27 | 265.15 | -9.04 | 94.1 | 3.27 | 3.08 | 0.19 | 1.92 | 3.09 | 1309.00 | 0.32 | 0.63 | 214.3 |
如上所示,每10分钟记录一次观察值。这意味着在一个小时内,您将有6个观测值。同样,一天将包含144(6x24)次观察。
给定一个特定的时间,假设您要预测未来6小时的温度。为了做出此预测,您选择使用5天的观察时间。因此,您将创建一个包含最后720(5x144)个观测值的窗口以训练模型。许多这样的配置都是可能的,这使该数据集成为一个很好的实验对象。
下面的函数返回上述时间窗以供模型训练。该参数history_size是过去信息窗口的大小。这target_size是模型需要学习预测的未来时间。该target_size是需要被预测的标签。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
# Reshape data from (history_size,) to (history_size, 1)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels) |
在以下两个教程中,数据的前300,000行将是训练数据集,其余的将是验证数据集。总计约2100天的训练数据。
1 | TRAIN_SPLIT = 300000 |
设置种子以确保可重复性。
1 | tf.random.set_seed(13) |
第1部分:预测单变量时间序列
首先,您将仅使用一个特征(温度)训练模型,并在将来使用该模型为该值做出预测。
首先,我们仅从数据集中提取温度。
1 2 3 | uni_data = df['T (degC)'] uni_data.index = df['Date Time'] uni_data.head() |
###运行结果
记录时间
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
名称:T(degC),dtype:float64
让我们观察一下这些数据随时间变化的样子。
1 | uni_data.plot(subplots=True) |
数组([<matplotlib.axes._subplots.AxesSubplot对象位于0x7f7395c1ae10>],dtype = object)

随时间变化的样图
1 | uni_data = uni_data.values |
在训练神经网络之前缩放特征很重要。标准化是通过减去平均值并除以每个特征的标准偏差来进行缩放的一种常用方法。您还可以使用一种tf.keras.utils.normalize将值重新缩放到[0,1]范围内的方法。
注意:均值和标准差只能使用训练数据来计算。
1 2 | uni_train_mean = uni_data[:TRAIN_SPLIT].mean() uni_train_std = uni_data[:TRAIN_SPLIT].std() |
让我们标准化数据。
1 | uni_data = (uni_data-uni_train_mean)/uni_train_std |
现在让我们为单变量模型创建数据。对于第1部分,将为模型提供最后20个记录的温度观测值,并且需要学习预测下一个时间步长的温度。
1 2 3 4 5 6 7 8 9 | univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target) |
这就是univariate_data函数返回的内容。
1 2 3 4 | print ('Single window of past history')
print (x_train_uni[0])
print ('\n Target temperature to predict')
print (y_train_uni[0]) |
###运行结果
过去历史的单一窗口
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]
目标温度可预测
-2.1041848598100876
现在已经创建了数据,让我们看一个例子。提供给网络的信息以蓝色表示,并且它必须预测红叉处的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | def create_time_steps(length):
return list(range(-length, 0))
def show_plot(plot_data, delta, title):
labels = ['History', 'True Future', 'Model Prediction']
marker = ['.-', 'rx', 'go']
time_steps = create_time_steps(plot_data[0].shape[0])
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, x in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10,
label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future+5)*2])
plt.xlabel('Time-Step')
return plt |
1 | show_plot([x_train_uni[0], y_train_uni[0]], 0, 'Sample Example') |
##运行结果
<来自/home/kbuilder/.local/lib/python3.6/site-packages/matplotlib/pyplot.py的模块'matplotlib.pyplot'>

第一次未来预测
基准线
在继续训练模型之前,让我们首先设置一个简单的基准。在给定输入点的情况下,基线方法将查看所有历史记录,并预测下一个点是最近20个观测值的平均值。
1 2 3 4 5 | def baseline(history):
return np.mean(history)
show_plot([x_train_uni[0], y_train_uni[0], baseline(x_train_uni[0])], 0,
'Baseline Prediction Example') |
##运行结果
<来自/home/kbuilder/.local/lib/python3.6/site-packages/matplotlib/pyplot.py的模块'matplotlib.pyplot'>

基线预测示例
让我们看看您是否可以使用递归神经网络超越这一基线。
递归神经网络
递归神经网络(RNN)是一种非常适合时间序列数据的神经网络。RNN分步处理时间序列,维护内部状态,以汇总到目前为止所见信息。有关更多详细信息,请阅读RNN教程。在本教程中,您将使用一个称为RNN的专用RNN层(LSTM)
现在tf.data,我们使用它来随机整理,批处理和缓存数据集。
1 2 3 4 5 6 7 8 | BATCH_SIZE = 256 BUFFER_SIZE = 10000 train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni)) train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat() val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni)) val_univariate = val_univariate.batch(BATCH_SIZE).repeat() |
以下可视化效果应有助于您理解批处理后数据的表示方式。

Time steps
您将看到LSTM需要给出的数据的输入形状。
1 2 3 4 5 6 | simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae') |
让我们进行样本预测,以检查模型的输出。
1 2 | for x, y in val_univariate.take(1):
print(simple_lstm_model.predict(x).shape) |
##结果输出
(256,1)
让我们现在训练模型。由于数据集的大小很大,为了节省时间,每个纪元将仅运行200个步骤,而不是像通常那样运行完整的训练数据。
1 2 3 4 5 6 | EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_univariate, validation_steps=50) |
###运行结果
训练200步,验证50步
时代1/10
200/200 [==============================]-2s 11ms / step-损耗:0.4075-val_loss:0.1351
时代2/10
200/200 [==============================]-1s 4ms / step-损耗:0.1118-val_loss:0.0360
时代3/10
200/200 [==============================]-1s 4ms / step-损耗:0.0490-val_loss:0.0289
时代4/10
200/200 [==============================]-1s 4ms / step-损耗:0.0444-val_loss:0.0257
时代5/10
200/200 [==============================]-1s 4ms / step-损耗:0.0299-val_loss:0.0235
时代6/10
200/200 [==============================]-1s 4ms / step-损耗:0.0317-val_loss:0.0224
时代7/10
200/200 [==============================]-1s 4ms / step-损耗:0.0287-val_loss:0.0206
时代8/10
200/200 [==============================]-1s 4ms / step-损耗:0.0263-val_loss:0.0200
时代9/10
200/200 [==============================]-1s 4ms / step-损耗:0.0254-val_loss:0.0182
时代10/10
200/200 [==============================]-1s 4ms / step-损耗:0.0228-val_loss:0.0174
使用简单的LSTM模型进行预测
既然您已经训练了简单的LSTM,让我们尝试做一些预测。
1 2 3 4 | for x, y in val_univariate.take(3):
plot = show_plot([x[0].numpy(), y[0].numpy(),
simple_lstm_model.predict(x)[0]], 0, 'Simple LSTM model')
plot.show() |

Simple LSTM model

Simple LSTM model

output_S2rRLrs8MtGU_2
这看起来比基线更好。既然您已经了解了基础知识,那么让我们继续第二部分,在这里您将使用多元时间序列。
第2部分:预测多元时间序列
原始数据集包含十四个特征。为简单起见,本节仅考虑原始的十四个中的三个。使用的功能是气温,大气压力和空气密度。
要使用更多功能,请将其名称添加到此列表中。
1 2 3 4 | features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)'] features = df[features_considered] features.index = df['Date Time'] features.head() |
运行结果:
| p (mbar) | T (degC) | rho (g/m**3) | |
|---|---|---|---|
| Date Time | |||
| 01.01.2009 00:10:00 | 996.52 | -8.02 | 1307.75 |
| 01.01.2009 00:20:00 | 996.57 | -8.41 | 1309.80 |
| 01.01.2009 00:30:00 | 996.53 | -8.51 | 1310.24 |
| 01.01.2009 00:40:00 | 996.51 | -8.31 | 1309.19 |
| 01.01.2009 00:50:00 | 996.51 | -8.27 | 1309.00 |
让我们看一下这些功能在时间上的变化。
1 | features.plot(subplots=True) |
##运行结果
array([,
<位于0x7f7394c88e10的,
],
dtype = object)

预测多元时间序列
如前所述,第一步将是使用训练数据的均值和标准差对数据集进行标准化。
1 2 3 4 5 | dataset = features.values data_mean = dataset[:TRAIN_SPLIT].mean(axis=0) data_std = dataset[:TRAIN_SPLIT].std(axis=0) dataset = (dataset-data_mean)/data_std |
单步模型
在一步设置中,模型将根据提供的某些历史记录来学习预测未来的单个点。
下面的函数执行与下面相同的加窗任务,但是,此处它根据给定的步长对过去的观察进行采样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels) |
在本教程中,将向网络显示最近五(5)天的数据,即每小时采样720个观测值。每隔一小时进行一次采样,因为预计60分钟内不会发生剧烈变化。因此,120次观察代表最近五天的历史。对于单步预测模型,数据点的标签是未来12小时的温度。为了为此创建标签,使用72(12 * 6)次观察后的温度。
1 2 3 4 5 6 7 8 9 10 11 12 | past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP,
single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP,
single_step=True) |
让我们看一个数据点。
1 | print ('Single window of past history : {}'.format(x_train_single[0].shape)) |
##运行结果
过去历史的单个窗口:(120,3)
1 2 3 4 5 6 7 8 9 10 11 12 13 | train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32,
input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae') |
让我们看看样本预测。
1 2 | for x, y in val_data_single.take(1): print(single_step_model.predict(x).shape) |
##运行结果
(256,1)
1 2 3 4 | single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50) |
##运行结果
训练200步,验证50步
时代1/10
200/200 [==============================]-4s 18ms / step-损耗:0.3090-val_loss:0.2646
时代2/10
200/200 [=============================]-2s 9ms / step-损耗:0.2624-val_loss:0.2435
时代3/10
200/200 [=============================]-2s 9ms / step-损耗:0.2616-val_loss:0.2472
时代4/10
200/200 [=============================]-2s 9ms / step-损耗:0.2567-val_loss:0.2442
时代5/10
200/200 [==============================]-2s 9ms / step-损耗:0.2263-val_loss:0.2346
时代6/10
200/200 [=============================]-2s 9ms / step-损耗:0.2416-val_loss:0.2643
时代7/10
200/200 [==============================]-2s 9ms / step-损耗:0.2411-val_loss:0.2577
时代8/10
200/200 [==============================]-2s 9ms / step-损耗:0.2410-val_loss:0.2388
时代9/10
200/200 [=============================]-2s 9ms / step-损耗:0.2447-val_loss:0.2485
时代10/10
200/200 [==============================]-2s 9ms / step-损耗:0.2388-val_loss:0.2422
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
##查看下运行结果
plot_train_history(single_step_history,
'Single Step Training and validation loss') |

Single Step Training and validation loss
预测未来的一步
现在已经对模型进行了训练,让我们进行一些样本预测。该模型具有每小时过去5天采样的三个要素的历史记录(120个数据点),因为目标是预测温度,所以该图仅显示过去的温度。预测是在未来一天进行的(因此,历史记录和预测之间存在差距)。
1 2 3 4 5 | for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show() |

Single step Prediction
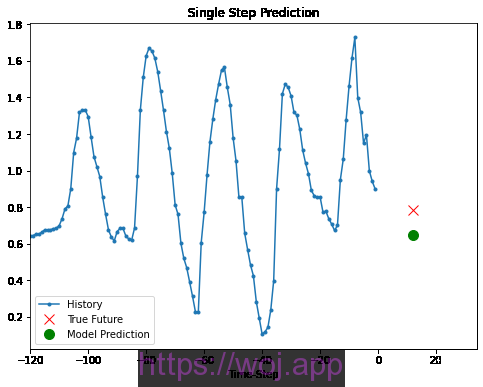
Single step Prediction
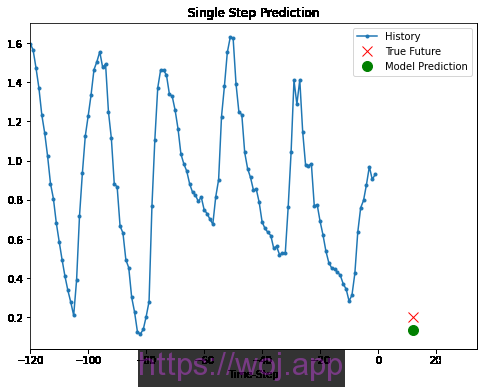
Single step Prediction
多步模型
在多步骤预测模型中,给定过去的历史,该模型需要学习预测一系列未来值。因此,与仅预测单个未来点的单步模型不同,多步模型预测未来的序列。
对于多步骤模型,训练数据再次包括每小时采样的过去五天的记录。但是,这里的模型需要学习预测接下来12小时的温度。由于每10分钟进行一次反驳,因此输出为72个预测。对于此任务,需要相应地准备数据集,因此第一步只是再次创建它,但使用不同的目标窗口。
1 2 3 4 5 6 7 | future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP) |
让我们检查一个样本数据点。
1 2 | print ('Single window of past history : {}'.format(x_train_multi[0].shape))
print ('\n Target temperature to predict : {}'.format(y_train_multi[0].shape)) |
##运行结果
过去历史的单个窗口:(120,3)
预测目标温度:(72,)
1 2 3 4 5 | train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi)) train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat() val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi)) val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat() |
绘制样本数据点。
1 2 3 4 5 6 7 8 9 10 11 12 13 | def multi_step_plot(history, true_future, prediction):
plt.figure(figsize=(12, 6))
num_in = create_time_steps(len(history))
num_out = len(true_future)
plt.plot(num_in, np.array(history[:, 1]), label='History')
plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',
label='True Future')
if prediction.any():
plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',
label='Predicted Future')
plt.legend(loc='upper left')
plt.show() |
在此图和后续类似图中,每小时都会采样历史记录和将来的数据。
1 2 | for x, y in train_data_multi.take(1): multi_step_plot(x[0], y[0], np.array([0])) |

多步模型
由于此处的任务比先前的任务复杂一些,因此该模型现在由两个LSTM层组成。最后,由于进行了72个预测,因此密集层将输出72个预测。
1 2 3 4 5 6 7 8 | multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,
return_sequences=True,
input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))
multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae') |
让我们看看模型在训练之前如何预测。
1 2 | for x, y in val_data_multi.take(1): print (multi_step_model.predict(x).shape) |
##运行结果
(256,72)
1 2 3 4 | multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_multi,
validation_steps=50) |
##运行结果
训练200步,验证50步
时代1/10
200/200 [==============================]-21s 103ms / step-损耗:0.4952-val_loss:0.3008
时代2/10
200/200 [=============================]-18s 89ms / step-损耗:0.3474-val_loss:0.2898
时代3/10
200/200 [==============================]-18s 89ms / step-损耗:0.3325-val_loss:0.2541
时代4/10
200/200 [=============================]-18s 89ms / step-损耗:0.2425-val_loss:0.2066
时代5/10
200/200 [=============================]-18s 89ms / step-损耗:0.1963-val_loss:0.1995
时代6/10
200/200 [=============================]-18s 90ms / step-损耗:0.2056-val_loss:0.2119
时代7/10
200/200 [=============================]-18s 91ms / step-损耗:0.1978-val_loss:0.2079
时代8/10
200/200 [=============================]-18s 89ms / step-损耗:0.1957-val_loss:0.2033
时代9/10
200/200 [=============================]-18s 90ms / step-损耗:0.1977-val_loss:0.1860
时代10/10
200/200 [==============================]-18s 88ms / step-损耗:0.1904-val_loss:0.1863
1 | plot_train_history(multi_step_history, 'Multi-Step Training and validation loss') |

多步模型
预测多步未来
现在让我们看一下您的网络在预测未来方面的学习情况。
1 2 | for x, y in val_data_multi.take(3): multi_step_plot(x[0], y[0], multi_step_model.predict(x)[0]) |

预测未来方面的学习情况

预测未来方面的学习情况

预测未来方面的学习情况
下一步
本教程是使用RNN进行时间序列预测的快速介绍。您现在可以尝试预测股票市场并成为亿万富翁。
另外,您还可以编写一个生成器来生成数据(而不是uni / multivariate_data函数),这将提高内存效率。您也可以查看此时间序列窗口指南,并在本教程中使用它。
为了进一步理解,您可以阅读《使用Scikit-Learn,Keras和TensorFlow进行动手机器学习》(第2版)的第15章和《使用Python进行深度学习》的第6章。
文章来源:https://tensorflow.google.cn/tutorials/structured_data/time_series
布施恩德可便相知重
微信扫一扫打赏
支付宝扫一扫打赏